When containers become unhealthy in production environments, a nuclear action is often the best option. When it comes to a security alert however, a different approach is needed. Nuclear actions have been the default answer for too long – there are better ways to handle the encompassing analysis, visibility, and containment for a container that can benefit security analysts in the process. We saw a gap in industry resources that covered these parts in a whole and in the context of analysis and containment... so we created a cumulative resource for our use at Target tech, and wanted to share it out with the community.
Docker created the common use of containers in the information technology sector in 2013. While hardening these containers has been an ongoing effort, responding to them is relatively new. There are a variety of container monitor solutions with the main purpose to perform health checks based on baselines or thresholds, but due to the nature of a container performing one action very well and immutability, the actions applied the container are far different than the actions that can be applied to the platform (host) that the container runs on.
Container Analysis
Design and access constraints are the biggest hurdles to interacting with a container. We want the container to not allow remote connections for user connections, which makes it a good practice to send an alert whenever a shell session spawns in a container that is running on a production environment.
In general, direct access to a container in a production environment should be extremely narrow or non-existent, and interacting with processes inside it through an exposed API the norm. When it comes to the design of the container, interactivity will be even less probable based on the limited resources and build file requirements of what capabilities it has.
Immutable containers still have a volatile part in the form of the runtime, which is the core of where the security artifact leftovers will live. Similar to a usual cyber incident response, proper analysis commands that one should attempt to collect or address volatile artifacts first.
A starting point would be to gather these, but not limited to these examples:
- Memory of the host/container (this could be dumping the memory for the process ID for the container on the platform/host level)
- What shares does it have access to? Underlying container networking is often complex and can sometimes only be in an internal container network / namespace. What permissions did the container have?
- What access does it have, ie root? Security context matters a lot, is it given special permissions? Is it being run as the host’s root user? Is the container user allowed to modify other files in the Docker image? Can it access files on the host via bind mounts or shared volumes with other containers?
- Network connections
- “logs” - Fetch the logs of a container. Docker container logs? Docker engine logs? There could also be logs in the container itself that you would not get access to via Docker logs command or the Docker engine logs. Containers often will also log to /var/log/ in the container itself which would only be present in the container’s running image.
- “top” - Display the running processes of a container
- “diff”- Inspect changes to files or directories on a container’s file system
- “stats” - Display a live stream of container(s) resource usage statistics
- If access to Docker/orchestration is available, get stats from running container:
Your next step would be to clone the container. Depending on the method of cloning, the chances of loss in the memory or runtime will be high, especially anything not written to disk.
Container Visibility and Detection
You can gain container visibility by deploying an auditing tool such as Auditd that has the ability to log specific sys calls at the Linux kernel. Once that’s enabled, you gain the ability to log process executions from the host and from within the container because the host shares its kernel with the container.
Example audit rule:
-a always,exit -F arch=b64 -S execve -k execExample audit rule:
host> curl www.google.com host> docker exec -it adoring_keldysh /bin/sh container> wget www.google.comHost logs:
#1 curl:
{ "args": [ "curl", "www.google.com" ], "executable": "/usr/bin/curl", "name": "curl", "pid": 4066, "ppid": 3009, "title": "curl www.google.com", "working_directory": "/home/ubuntu" }#2 docker exec:
{ "args": [ "docker", "exec", "-it", "adoring_keldysh", "/bin/sh" ], "executable": "/usr/bin/docker", "name": "docker", "pid": 8077, "ppid": 3891, "title": "docker exec -it adoring_keldysh /bin/sh", "working_directory": "/home/ubuntu" }Container log (logged by the host):
#1 start of sh:
{ "args": [ "/bin/sh" ], "executable": "/bin/busybox", "name": "sh", "pid": 8103, "ppid": 8093, "title": "/bin/sh", "working_directory": "/" }#2 wget:
{ "args": [ "wget", "www.google.com" ], "executable": "/bin/busybox", "name": "wget", "pid": 8172, "ppid": 8103, "title": "wget www.google.com", "working_directory": "/" }With these example logs, we can detect the start of a new terminal within the container, suspicious commands executed within the container, and also suspicious executions of Docker. These logs are outside of the container – on the host itself – so these artifacts can be reviewed or collected even after a container has been removed from the host.
Container Containment
The containment and isolation of a container go hand-in-hand, but are not equal.
The isolation of a container is primarily used to segment an infection spread (lateral movement, exfil, etc.) as well as to create more time and opportunities for analysis to occur. You can do that a number of ways, but two are especially noteworthy:
- With an orchestration platform, firewall rules can be applied to a single container with “tags” that can only talk to only whitelisted items.
- Migrate a container to a segmented network of the platform that has designs for no external comms and only slim internal coms to protected items for Cyber Security analysts to interact with protective measurements in place.
Containment can only occur if an infection has stopped, and there’s not a possibility of it reoccurring. While isolation is a part of it, before going into the large cloud platforms, it is important to also mention the smaller platforms, i.e., the user’s host. Because most development occurs first on a user host before they start trying it in a bigger cluster, it is crucial to understand how to isolate them as well. The good thing is it is relatively easy to isolate a single host.
The balancing act of prevention measures in place and time to refactor code of the container come into play when it comes to these large deployments of containers.
Take two attack scenarios: code poison and zero-day. Code poison can happen in many ways, one of which could be using an attacker-controlled library. With zero day, it’s important to know if you can identify an attacker similar to Account Take-Over activity to slow the exploitation of the container while the developer is refactoring code?
The figure below shows another scenario as well as the types of response actions needed for it.
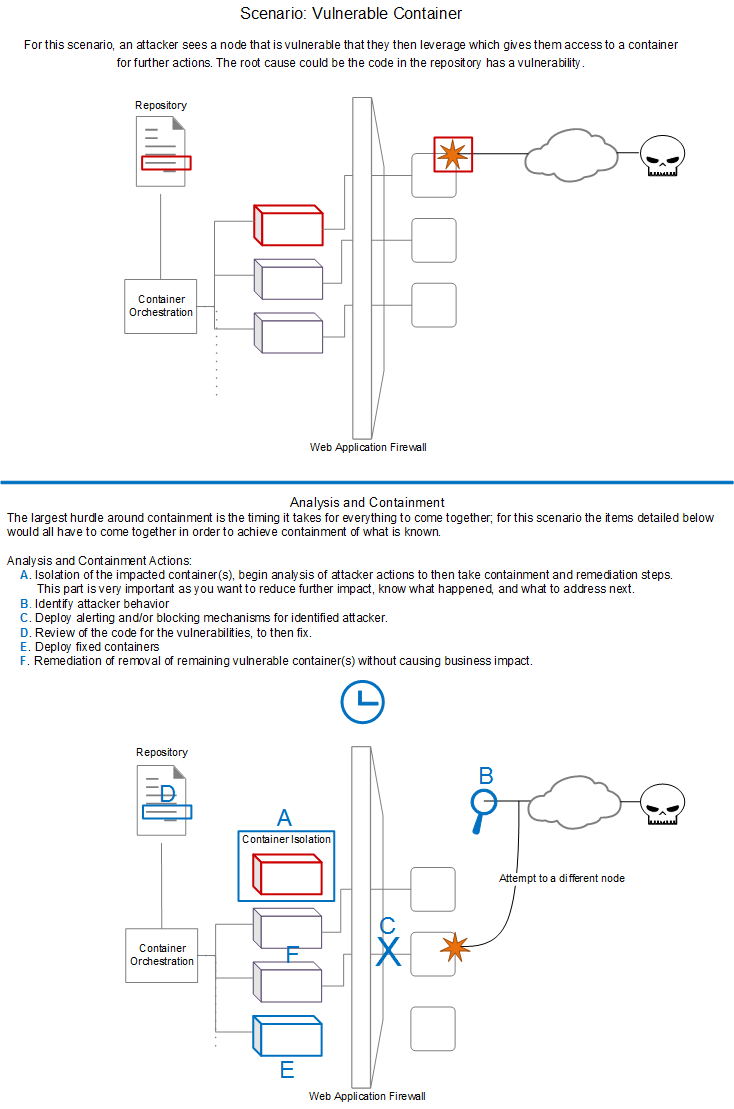
Conclusion
Knowing the beginning of where to start when responding to events around containers is going to be critical for successful containment and remediation. While we’ve discussed a few items here, they only scratch the surface of the advancement that will come in the next few years around container-related incident response.
These generic examples were meant to help readers gain a general understanding of the topic, but there are many more scenarios and technical obstacles that come into play for individual organizations in regard to their cloud and compute infrastructure. That said, applying these basic principles is a good start to finding solutions for the containment of a container.
________________________________________________________
Researchers
- Grant Sales, a Principal Engineer in Cyber Security, focusing on Threat Detection and Security Visibility
- Kyle Shattuck, a Principal Analyst in Cyber Security, focusing on Incident Response
- Allen Swackhamer, a Principal Engineer in the Cyber Fusion Center, focusing on Cyber Threat Intelligence tool development