Author’s note:
Last Sunday was Father’s Day in the U.S. and I found myself thinking back to what’s known internally as “the Father’s Day incident” – a tech issue that occurred in 2019. Though this was not recent, our team’s learnings continue to guide Target’s tech and engineering processes today – so much so, that we think an internal recap from a few years ago remains relevant for other engineering teams operating in complex and distributed systems. One of Target’s core values is "drive" – learn through progress over perfection – and we hope this analysis helps others learn alongside.
What follows is our account of “the Father’s Day incident” which significantly changed, for the better, how we operate enterprise technology at Target. We share more broadly how we use architecture to continually improve our system resiliency and how we actively engineer to mitigate and reduce the impact of service outages.
Introduction
In 2017, Target announced that we had prioritized stores at the center of how we serve our guests – no matter how they choose to shop. To make this store-as-hubs model work, we spent several years redesigning operations and modernizing how we conduct business. We invested billions of dollars into remodeling stores, hardened our world-class supply chain, and created a robust suite of fulfillment options to meet every guest need.
Technology helps enable the model and push the boundaries of the omnichannel retail services that Target offers. With nearly 2,000 stores, we’ve had to create new solutions to ensure that each store can operate both independently and as part of the whole. Like every company pioneering new paths forward, we’ve had missteps along the way, but we’ve always made sure to learn and progress from them as well.
What Happened
On Saturday, June 15, 2019, the day before Father’s Day in the U.S., Target experienced an outage over approximately two hours where the point of sale (POS) registers were unable to scan guest items during the checkout process. This impact affected all Target stores simultaneously – around 1,800 at the time – causing widespread delays in guest checkouts. The incident began around 12:35 pm CT when the Target Client Support Center (CSC) began receiving significant call volume from our store team members about the inability to scan and sell items.
At this point, no monitoring systems for store-related operations had triggered alerts indicating an issue at either a software or infrastructure layer. Initial investigations evaluated the state of common core services that could impact all stores simultaneously including wide area networking (WAN) and Identity and Access Control. After verifying that these systems were operating normally and that no configuration changes had been applied to them, response teams were engaged to begin evaluating all systems involved in the register functions.
By 1:24 pm CT, those teams identified a significant increase in error responses from the Item Location Service (ILS). ILS is a core data API that provides details about products. At approximately 2:32 pm CT, the teams were able to mitigate the issues causing the increased error rate and stores began to successfully scan and checkout guest purchases again.
Our technology teams continued to be engaged to identify a root cause for the increased error rate and subsequently identified an overall increase in request rate to the ILS service that was not in-line with expected request rates for that service. At approximately 4:05 pm CT, the ILS service again began to experience increased load and latency, causing instances to become unhealthy. By 4:10 pm CT, the teams had identified the root cause of both the increased request and error rates and began rolling a fix out to all stores using our automated store deployment system, Unimatrix. By 4:36 pm CT all stores received the update and the API request and error rates subsided.
Background
Target’s application architecture, known internally as the Target Retail Platform, is a distributed microservice architecture that relies on service-to-service HTTP calls and streaming data platforms to move business data between Target’s data centers and edge locations such as a store or distribution center. This design allows multiple engineering teams to develop and deploy various internal products and applications independently of each other with minimal direct dependencies that require coordinated releases between product teams.
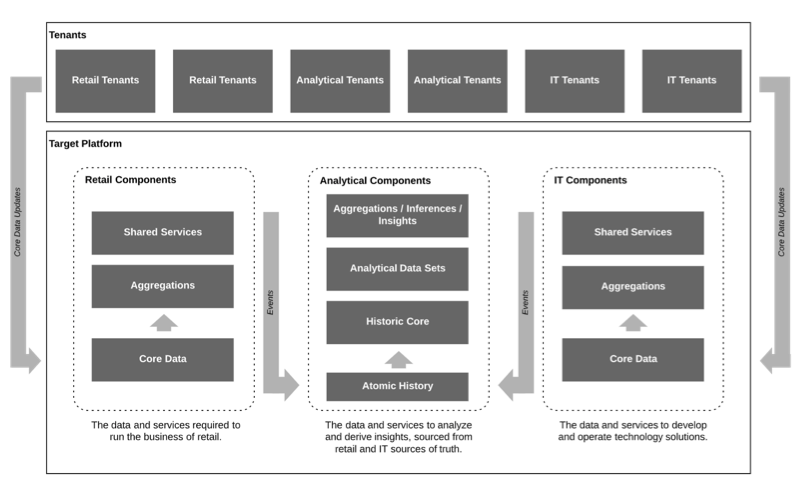
Each Target store hosts a compute environment that provides local data and business services for the many applications running such as the registers, kiosks, team member mobile devices, internet of things (IoT) platform, and supply chain and fulfillment management software. Each store and distribution center can communicate with Target’s private data centers over a dedicated Wide Area Network (WAN) link. Under normal conditions, each Target store operates as an isolated environment from Target’s data centers by moving core business data like item information to the store through an asynchronous store data movement (SDM) system. The first step of this process is to replicate core data from the data centers to a forward cache in each store through a distributed cache system called Autobahn.
Once in the store, Autobahn data is accessible via the SDM Proxy API. The SDM Proxy acts as an in-store API gateway routing requests from client applications (such as POS) to the appropriate backend. SDM Proxy both abstracts backend technologies (such as Autobahn) and allows for implementation of resiliency patterns (such as requesting the data from a redundant data source in the case that Autobahn is missing the requested data). In the case of item data, SDM Proxy falls back to requesting the data from the Item Location Service (ILS) hosted in Target’s data centers.
Requests to core data APIs in the data centers are routed through our API Platform. The API Platform consists of an API Gateway which maps requests to the corresponding backend service and an on-instance authentication/authorization proxy, Go-Proxy, which is typically deployed as a sidecar container and initially receives the request from the API Gateway.
Finally, high profile processes (such as POS) implement their own fallback processes to handle the possibility of issues with the SDM system in store. In the case of item data, the POS software on each register is capable of bypassing the SDM Proxy and retrying its request directly to the ILS API in the data centers.
Root Cause
Beginning on June 3, 2019, a configuration change was rolled out to the stores topology that enabled a new feature. Inadvertently, the change also included an error in the routing configuration of item data. The resulting configuration created a mismatch in URIs between the SDM Proxy and Autobahn APIs. This resulted in SDM Proxy making requests to a non-existent Autobahn endpoint and getting 404 responses. Although Autobahn contained all the item data, the 404 responses were interpreted by the SDM Proxy as an indicator that the item was missing in Autobahn and the SDM Proxy retried the request to the central ILS API in the data centers. The SDM Proxy change was deployed through our normal processes to approximately 10% of the stores footprint before finally being deployed to all stores on June 10. The effects of the configuration change were not immediately apparent due to the fallback path successfully responding to requests within the specified SLA for the POS software.
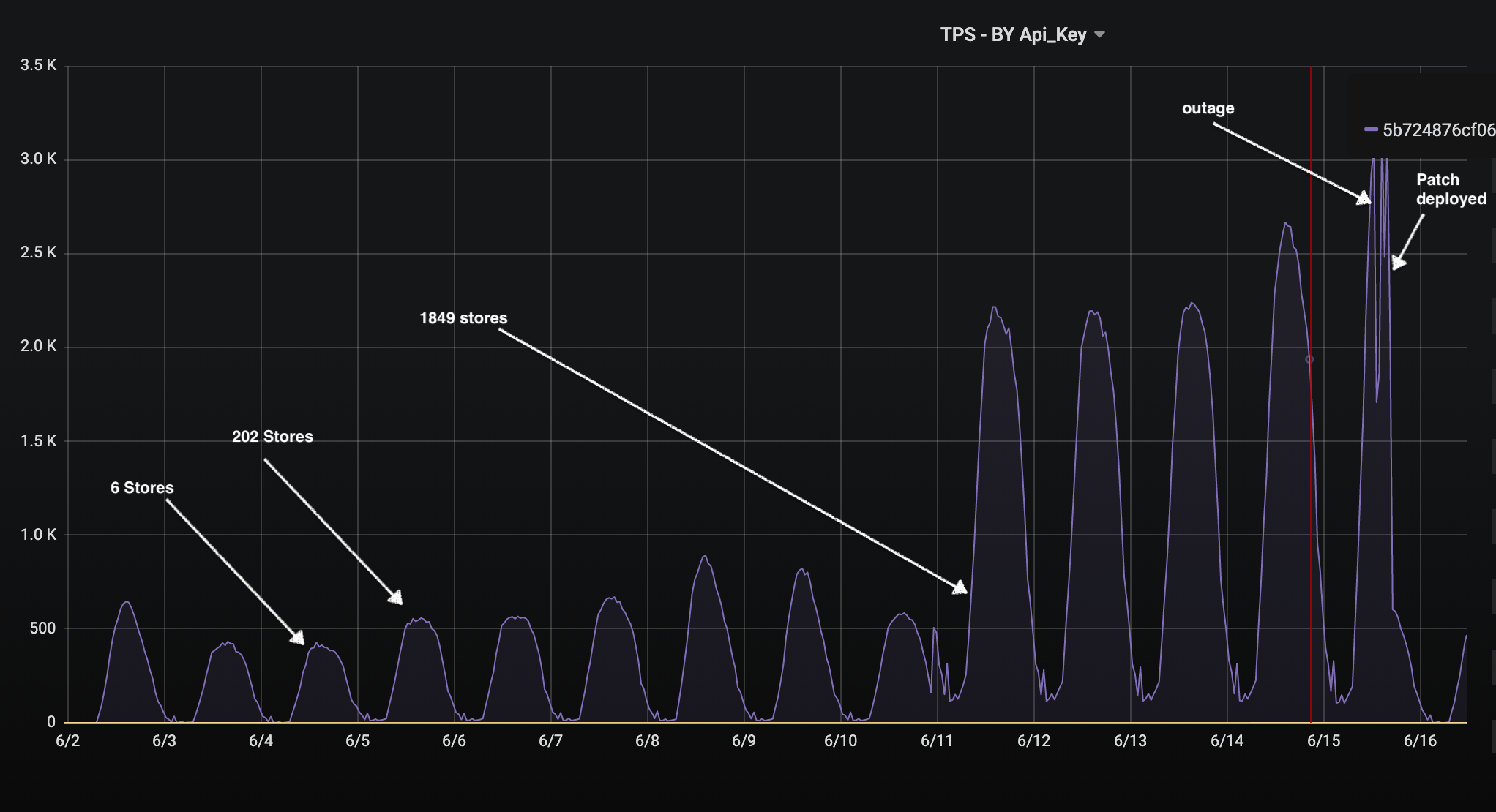
With all store traffic being routed to the data center and an increase in normal store traffic due to the weekend and upcoming Father’s Day holiday, the total request traffic being handled by ILS in the data centers exceeded the operational capabilities of the provisioned resources. As ILS approached its operational thresholds it began to create a thundering herd effect. As ILS began to struggle to service requests within its SLA, upstream clients like SDM Proxy began retrying requests due to the errors. The net effect of this retry was to further increase load on ILS which continued to degrade in performance. This further degradation created back pressure on SDM Proxy in each store, which passed the latent response times back to calling applications like POS. Since POS implements its own failover logic, it then began bypassing SDM Proxy and retrying requests directly to ILS. In total, this resulted in an approximately 4x increase in requests received by ILS.
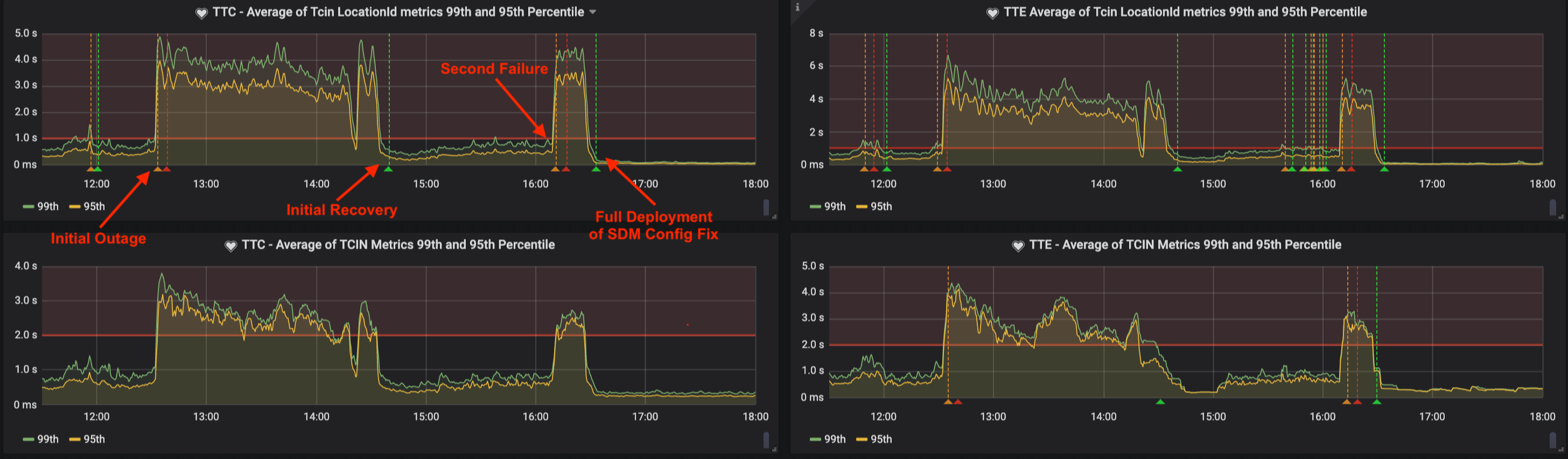
Ultimately, instances of ILS were under such strain that they began failing health checks and were removed from the load balancer pools resulting in further load on the remaining healthy instances. This created a cycle where healthy instances would be forced unhealthy by the load and unhealthy instances would become healthy once their load was removed only to become unhealthy again once placed under load. At the peak of the incident, only about 50% of ILS instances were healthy at any given time.

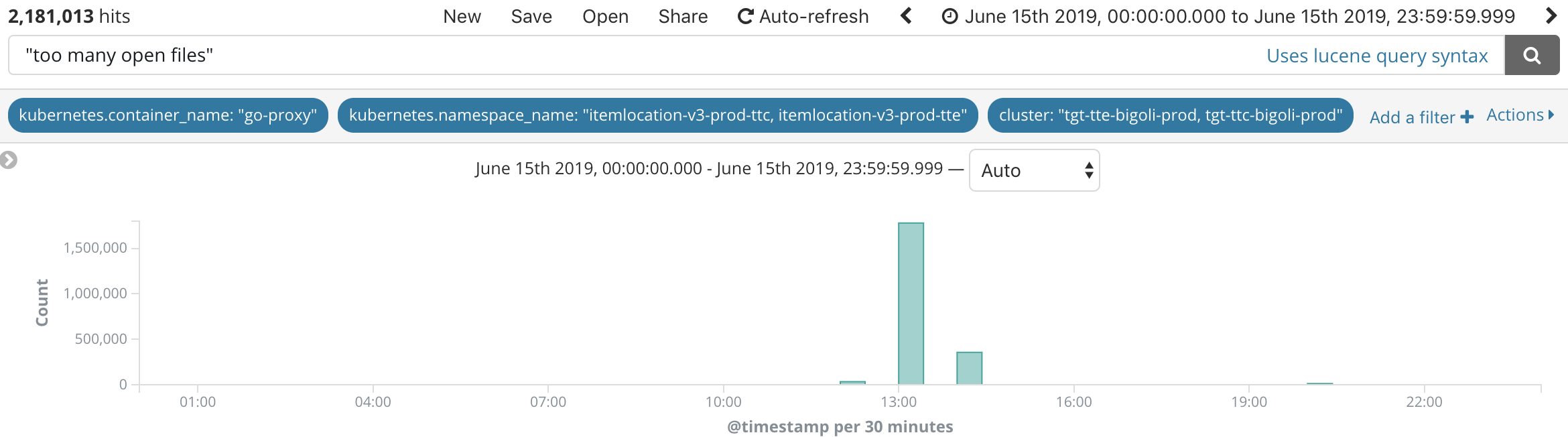
ILS runs in our data centers on a series of multi-tenant clusters. Investigation into the ILS pod health revealed that the application container and its Go-Proxy sidecar process were experiencing two issues – first, 95th percentile read times to the underlying datastore reached 1.5 seconds and second, the Go-Proxy process was suffering from open file exhaustion on the underlying workers. The elevated read times were likely due to the increased load created by the herd effect as all stores and registers retried calls back to the central ILS API. The open file exhaustion was determined to be an issue in the configuration of the daemon on each node that incorrectly restricted the total maximum open file handles for all containers on that worker to 10,000.
The initial recovery at 2:32 pm CT was a result of the reduction of total traffic to ILS as team members in the stores began performing guest checkouts through manual entry of items and prices, bypassing item scans at the register. As the stores were made aware of the recovery and availability of item scans, guest checkouts began to switch back to the normal process using the registers. This then led to the load increase that triggered the second failure at 4:05 pm CT, which lasted until the SDM Proxy configuration change was deployed to stores with final recovery at 4:36 pm CT.
Resolution
Resolving the incident required addressing both underlying issues in the system. First, additional capacity was scaled up for ILS in the data centers. Second, a patch to correct the error in the SDM Proxy configuration was applied to allow POS requests to reach Autobahn endpoints and prevent the SDM Proxy from falling back to ILS in the data centers. The patch was first deployed to a test grouping of stores to verify the corrected behavior before being rolled out nationwide. Once verified, Unimatrix allowed us to roll the configuration change to all stores within minutes. As the patch was applied to stores, the POS software in the store began functioning correctly allowing for item scans at the registers and the request load on ILS returned to minimal levels.
What Went Wrong
There were three major areas where we did not live up to the high operational expectations that we place on ourselves. First, although the original configuration change made to the SDM proxy had been rolled out via the normal stores process, the change in behavior to route all traffic back to the data centers was not identified during the roll out. This change resulted in a configuration that placed ILS in a high-risk state.
Second, there were multiple points between the POS software and the ILS instances in the data centers where we could have detected the sudden shift in request behavior but did not. Although the metrics that indicated this behavior were being collected, no alert thresholds had been configured.
Third, the increase in request latency and sudden loss of capacity in ILS which was the primary cause of the outage went unidentified for over 1.5 hours. Coincidentally, 99th percentile latency on ILS was one place in the chain where an alert threshold was defined and triggered during the incident. However, the alert was not correlated to the ongoing incident as a cause.
Lessons and Path Forward
Engineers across Target, including those who did not work on the affected systems, responded without hesitation to assist in the troubleshooting and resolution. After recovery, we were able to immediately collect all the data concerning the outage. We performed an exhaustive analysis to fully understand the various conditions and failures that resulted in the outage. And as with any good self-analysis, we identified many opportunities for improvement to mitigate issues like this again.
The most obvious lesson is that we needed to improve observability across our systems and services with particular focus in areas where we’ve implemented patterns to improve stability and resiliency. We missed both the initial lead up and the specific failure at the root of this outage. It took our teams responding to the incident far too long to identify the issue and determine a recovery action. It’s not enough to implement redundant systems and failovers, we must monitor and alert when those systems are being exercised.
Redundant systems and backups are only valid to the extent of the capability that they can provide when being employed. In this outage, our secondary systems performed their jobs as designed – store traffic was routed and handled by the central APIs in the data centers. However, at design time, we failed to identify a full, nationwide fallback as a failure mode for our systems. Thus, our backup systems were untested and under-allocated for this failure.
One of the most complex patterns in a widely distributed system is how to handle cascading failure conditions. As discussed above, many of the systems involved in this outage implemented error and failure handling by retrying the associated requests to fall back paths. However, these patterns amplified the load on the downstream services because of arbitrarily configured timeouts at multiple layers and a lack of traffic shaping and circuit breakers. We revisited our design patterns in this area to more clearly define which services are responsible for failover at the edge, how we propagate request timeout through the entire dependency chain for a request, and how we manage worst case error conditions.
Contributions from Greg Case, Amit Dixit*, Meredith Jordan, Abhilash Koneri, Mike Muske, Dan Nevers, Saravan Periyasamy*, Isaac Schwoch*, and Manuel Quinones.
Additional information from Kate Ash, Cameron Becker, Brian Cavanaugh, Jay Chandrashekaren*, Rahul Chokhani*, Mark Christenson*, James Christopherson, Zachary Evans, Amy Evenson, Steve Hebert*, Jill Jakusz, Greg Larson, Kraig Narr, Collin Nelson, John Olson*, Daniel Parker, Mayur Purandar*, Eddie Roger*, Annette Schultz, Jayachandran Siva*, Tolga Umut, Erich Weidner, and Connie Yu.
*indicates that this individual is no longer at Target.